Kubernetes – Guía para crear nuestro clúster (III)
A pesar de llevar un cierto tiempo usando Kubernetes en producción, ha sido este año cuando hemos comenzado a impartir las formaciones oficiales de la Linux Foundation, haciendo un foco especial en Kubernetes. Podéis comprobar nuestra oferta disponible en el catálogo de productos o en nuestra tienda virtual.
¿Qué es la Inteligencia Artificial ?
La Inteligencia Artificial (IA) es un campo de la informática que se centra en el desarrollo de sistemas y tecnologías que pueden realizar tareas que normalmente requerirían inteligencia humana. Estas tareas pueden incluir el reconocimiento de patrones, la resolución de problemas, la toma de decisiones, el procesamiento del lenguaje natural y la percepción sensorial, entre otras habilidades cognitivas. La IA se basa en algoritmos y modelos matemáticos que permiten a las máquinas aprender de los datos, adaptarse a nuevas situaciones y realizar acciones con autonomía. Su objetivo es desarrollar sistemas capaces de imitar e incluso superar las capacidades humanas en ciertos contextos específicos. La IA tiene aplicaciones en una amplia variedad de campos, incluyendo la medicina, la industria, la robótica, los servicios financieros, entre otros, y está en constante evolución con nuevos avances tecnológicos y descubrimientos.
Una de las áreas de aplicación más interesantes de la Inteligencia Artificial es en el campo de la computación de alto rendimiento, donde la capacidad de procesamiento paralelo de las GPU (Unidades de Procesamiento Gráfico) se está utilizando para acelerar el entrenamiento y la inferencia de modelos de aprendizaje automático y redes neuronales profundas.
¿Qué son los LLMs ?
Los LLMs (Large Language Models) son modelos de lenguaje que utilizan inteligencia artificial para comprender y generar texto de manera avanzada. Estos modelos están entrenados con grandes cantidades de datos textuales y son capaces de entender el contexto, la gramática y el significado detrás de las palabras. Pueden realizar tareas como responder preguntas, generar texto coherente y traducir entre idiomas. Los LLMs han avanzado mucho en los últimos años y se utilizan en una variedad de aplicaciones, desde asistentes virtuales hasta análisis de texto y generación de contenido.
¿Qué son los RAGs ?
Los RAGs (Retriever, Aggregator, Generator) son un tipo de modelo de lenguaje que combina técnicas de recuperación de información, agregación y generación de texto para mejorar la capacidad de los modelos de respuesta de preguntas y generación de texto.
- Retriever (Recuperador): Esta parte del modelo se encarga de buscar y recuperar información relevante de grandes bases de datos o corpus de texto para responder preguntas o generar contenido. Utiliza métodos de recuperación de información para encontrar la información más relevante para la consulta dada.
- Aggregator (Agregador): Después de recuperar la información relevante, el agregador filtra y combina la información recuperada para generar una respuesta coherente y precisa. Puede sintetizar múltiples fuentes de información para proporcionar una respuesta completa y bien informada.
- Generator (Generador): Finalmente, el generador utiliza la información recuperada y agregada para generar una respuesta final en forma de texto. Este componente se encarga de producir una respuesta legible y coherente utilizando técnicas de generación de lenguaje natural.
Los RAGs son una forma avanzada de mejorar la capacidad de los modelos de lenguaje para responder preguntas y generar contenido mediante la combinación de diferentes técnicas y enfoques. Este enfoque permite a los modelos abordar preguntas que requieren conocimientos más profundos o información específica más allá de lo que está presente en el entrenamiento inicial.
En nuestro post anterior, vimos cómo añadir nodos a nuestro clúster de Kubernetes. Para ello instalamos en el resto de nodos los componentes necesarios para establecer estos como «workers» o los que soportan la carga de trabajo.
En este caso vamos a configurar un nodo bastante particular. Añadiremos un nodo específico con una unidad de procesamiento gráfico (GPU) para potenciar nuestras cargas de trabajo de aprendizaje profundo, modelos de lenguaje de gran tamaño (LLM’s) y RAG (Retrieval-Augmented Generation). Este nodo estará equipado con todas las bibliotecas y dependencias necesarias para ejecutar estas tareas de manera eficiente, incluyendo TensorFlow, PyTorch, y otras librerías esenciales para el desarrollo y despliegue de aplicaciones de inteligencia artificial.
Descripción del Laboratorio
En esta guía, continuación de este post, vamos a utilizar equipos físicos como los nodos participantes de nuestro clúster de Kubernetes. En este laboratorio, prepararemos un escenario en el que necesitaremos el siguiente material:
- Equipos que funcionarán como nodos con GPU dedicada (NVIDIA RTX 4090)
- Un cable ethernet por cada nodo
- Un switch de red o router
Objetivos de la práctica
- Instalar los componentes del nodo worker GPU
- Instalar librerías y dependencias de NVIDIA
- Adopción del nodo worker.
- Verificar la configuración realizada.
Configuración paso a paso
1. Instalando componentes esenciales para nuestra GPU
Partimos de la base que tenemos el sistema operativo ya funcional, con una red para el clúster configurada y accesible por SSH. Además deberemos tener toda la instalación de nodo worker de Kubernetes que hicimos en el post anterior
Lo primero que haremos será instalar los drivers de nuestra tarjeta gráfica. En nuestro caso es una NVIDIA RTX 4090
apt-get update && apt-get upgrade -y
add-apt-repository ppa:graphics-drivers/ppa
apt-get update && apt-get install -y nvidia-driver-550
export PATH=/usr/local/cuda/bin:${PATH}
A continuación, instalamos CUDA que son las siglas de Compute Unified Device Architecture (Arquitectura Unificada de Dispositivos de Cómputo). Hace referencia a una plataforma de computación en paralelo que incluye un compilador y un conjunto de herramientas de desarrollo creadas por Nvidia que permiten a los programadores usar una variación del lenguaje de programación C (CUDA C) para codificar algoritmos en GPU de Nvidia.
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
dpkg -i cuda-keyring_1.1-1_all.deb
apt-get update
apt-get -y install cuda-toolkit-12-4
nvidia-smi
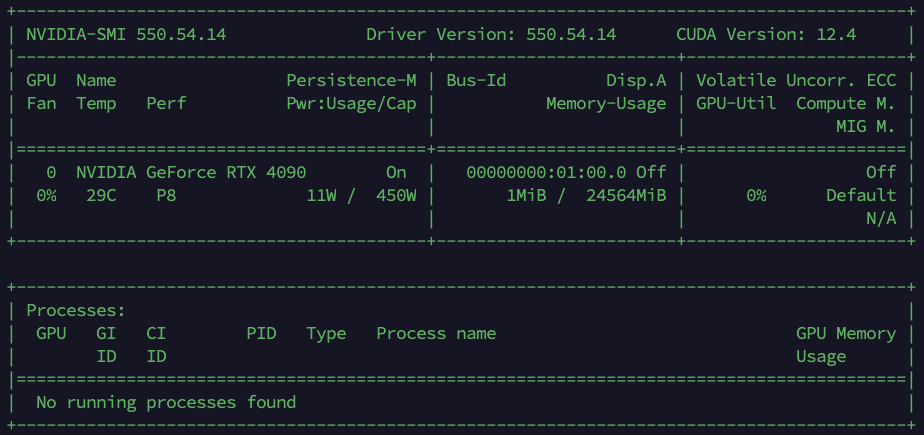
Una vez instalado el cuda-toolkit, necesitaremos instalar el kit de herramientas de containers especializado de Nvidia. Primero agregamos el repositorio.
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Actualizamos e instalamos el paquete de herramientas nvidia-container-toolkit
apt-get update && apt-get install -y nvidia-container-toolkit
Seguidamente, necesitaremos agregar el runtime de NVIDIA. Al ejecutar el siguiente comando, procedemos a modificar la configuración de containerd para agregar el runtime de NVIDA propiamente dicho. Luego comprobamos que se haya añadido correctamente esa parte de la configuración en el fichero correspondiente.
nvidia-ctk runtime configure --runtime=containerd nano /etc/containerd/config.toml
En el fichero se ha debido añadir algo similar a esto:
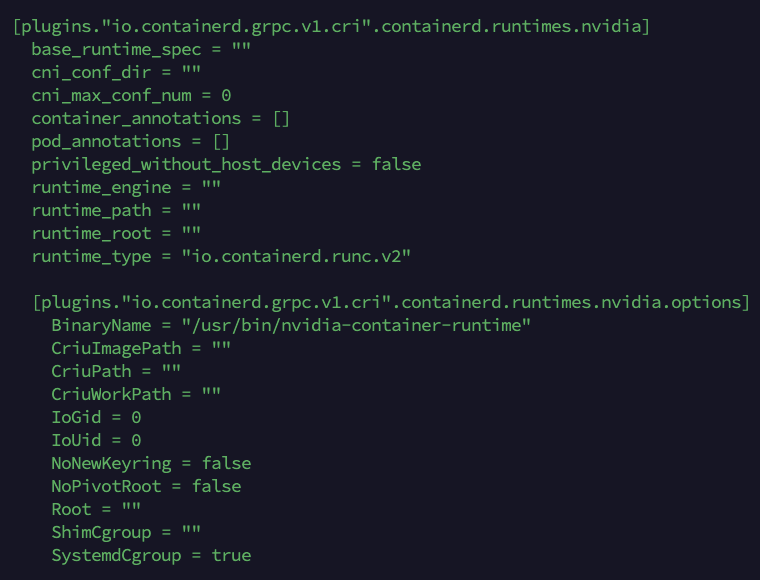
Reiniciamos el proceso containerd para aplicar los cambios en la configuración ya introducidos.
systemctl restart containerd
2. Instalando los NVIDIA GPU Operator
Kubernetes proporciona acceso a recursos de hardware especiales como GPUs NVIDIA, NICs, adaptadores Infiniband y otros dispositivos a través del framework de plugins de dispositivos. Sin embargo, la configuración y gestión de nodos con estos recursos de hardware requiere la configuración de múltiples componentes de software como controladores, tiempos de ejecución de contenedores u otras bibliotecas, lo que resulta difícil y propenso a errores. NVIDIA GPU Operator utiliza el marco del operador dentro de Kubernetes para automatizar la gestión de todos los componentes de software de NVIDIA necesarios para aprovisionar la GPU. Estos componentes incluyen los controladores NVIDIA (para habilitar CUDA), el plugin de dispositivos Kubernetes para GPUs, el NVIDIA Container Toolkit, el etiquetado automático de nodos mediante GFD, la monitorización basada en DCGM y otros.
Aprovechando la instalación de Helm que vimos en este post, usaremos un chart predefinido para descargarnos el gpu-operator de NVIDIA.
helm install --wait --generate-name \ -n gpu-operator --create-namespace \ nvidia/gpu-operator \ --set driver.enabled=false \ --set toolkit.enabled=false
Esta instalación, provocará un deployment de Kubernetes llamado gpu-operator en nuestro clúster, que se encargará de instalar, configurar y gestionar de manera apropiada los componentes necesarios para el uso de la GPU en el nodo correspondiente.
2. Verificaciones del correcto funcionamiento
Comprobamos los pods referidos al namespace gpu-operator
kubectl get -n gpu-operator pods
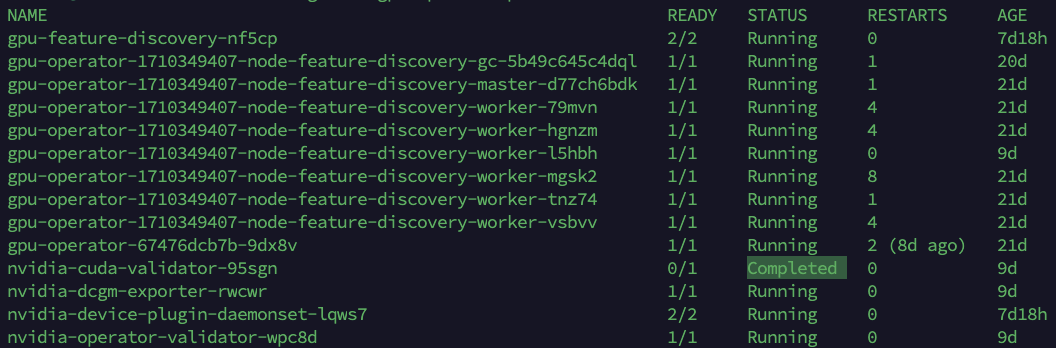
Podemos comprobar como el pod llamado nvidia-cuda-validator ha completado su ejecución de manera satisfactoria, lo que nos indica que el operador ha terminado de instalar todos los componentes necesarios para el uso de la GPU en nuestro clúster de Kubernetes.
Verificamos los recursos disponibles en nuestro nodo-worker con GPU
kubectl describe node nodo-worker-GPU
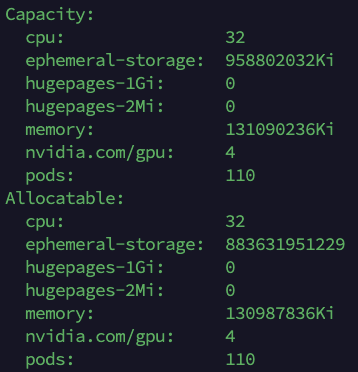
Visualizamos la disponibilidad del Kind RuntimeClass de NVIDIA en nuestro clúster
kubectl describe runtimeclasses.node.k8s.io
En esta parte, hemos configurado y puesto en funcionamiento nuestro nodo de Kubernetes con todo lo necesario para ejecutar cargas de trabajo en GPU dedicada a tal fin. La integración de una GPU dedicada de NVIDIA en un nodo de Kubernetes no solo representa un avance técnico significativo, sino que también abre un abanico de posibilidades para aplicaciones de Inteligencia Artificial (IA), Computación de Alto Rendimiento (HPC), etc. Al permitir una gestión eficiente de recursos y una escalabilidad dinámica, esta configuración optimizada ofrece un entorno ideal para desplegar cargas de trabajo intensivas en cómputo, mejorando tanto el rendimiento como la velocidad de procesamiento. Además, al aprovechar la potencia de las GPU, las aplicaciones de IA y HPC pueden experimentar mejoras sustanciales en términos de tiempo de entrenamiento, capacidad de análisis y capacidad predictiva. En resumen, la implementación de componentes de GPU de NVIDIA en un entorno de Kubernetes no solo facilita la infraestructura, sino que también impulsa la innovación y el progreso en campos críticos como la IA y la HPC.
En las certificaciones oficiales de Linux Foundation impartidas en loopback0, explicamos en profundidad los diferentes tipos de configuraciones para Kubernetes y sus diferentes aplicaciones.
